
Building Effective Custom Detection Rules
Introduction
At BSides Dresden, my colleague Jonas Schneidewind and I had the pleasure of presenting “Building Effective Custom Detection Rules – Lessons from the Field.” Our goal was to showcase how having a clear process for custom rules can prevent those dreaded late-night or holiday emergency fixes after a breach. While custom detection rules (DCRs) aren't a silver bullet, they significantly improve the odds of detecting a breach early, enabling faster remediation and minimizing damage.
This blog post is tailored for SOC analysts, detection engineers, CISOs, and anyone working in security who wants to avoid unnecessary overtime. ????
What is Detection Engineering and Why Do We Need It?
Detection engineering involves designing, testing, and maintaining detection logic to identify and respond to threats effectively. Unlike generic detections, custom rules are tailored to an organization’s unique environment.
Benefits:
- Reduced false negatives: Fewer incidents slip through undetected.
- Organization-specific rules: Tailored to your unique threat landscape.
- Early threat identification: Catch threats before they escalate.
Challenges:
- Resource-intensive: Requires time, effort, and expertise.
- Process gaps: Lack of structured workflows can hinder efficiency.
- Alert fatigue: Poorly designed rules can overwhelm SOC teams.
While custom detection engineering is a game-changer for fortifying defenses, it requires a strategic balance between benefits and resource allocation.
Proactive vs. Reactive Detection
Custom detection rules can be created using two approaches:

Proactive
Proactive detection focuses on identifying threats before they occur. By staying informed about the latest threat intelligence (TI), incidents in other organizations, and changes in your own environment, you can develop detection rules preemptively.
Advantages:
- Detect intrusions at an early stage.
- Prevent widespread compromises in your environment.
Reactive
In reactive detection, rules are created after an incident has occurred. This approach ensures any repeat incidents are quickly flagged and addressed.
Best Practice: After detecting a breach or exploit, prioritize building a detection rule to catch any subsequent attempts.
Real-Life Example: USB Drive Breach
In our session, we shared a real-life example involving a company breached through an employee plugging in an unknown USB drive.
Key Takeaways:
- Human behavior is unpredictable: While user actions are hard to fully account for in detection rules, educating employees can mitigate risks.
- Known malware can be preemptively detected: The XMRig miner malware in this case was well-documented, and proactive rules could have stopped it earlier in the attack chain.
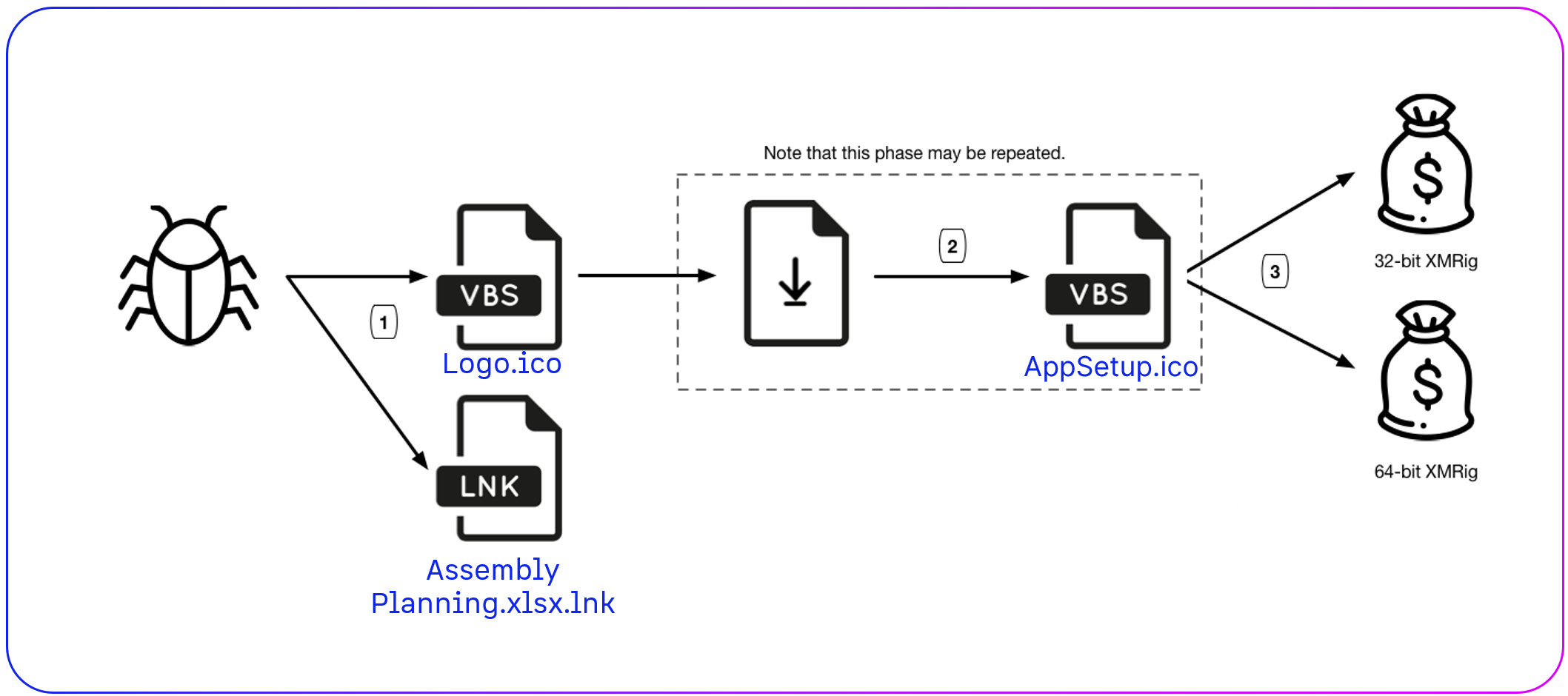
Attack Path Breakdown
Here’s how the XMRig miner infection unfolded:
Source: https://www.tripwire.com/state-of-security/15-million-people-worldwide-affected-single-monero-mining-operation
- User Action: An employee mistakenly clicked a malicious file (Assembly Planning.xlsx.lnk) on the USB drive, believing it was an Excel document.
- VBScript Execution: The file executed Logo.ico, a VBScript that downloaded additional malicious files.
- Malware Drop: AppSetup.ico executed, leading to the deployment of MProcHandler.exe and TProcHandler.exe. These processes enabled unauthorized cryptocurrency mining.
The Process for Building Custom Detection Rules
At Water, we’ve established a structured process to ensure our custom detection rules (DCRs) remain effective, adaptable, and responsive to evolving threat intelligence (TI), incidents, and organizational needs. Staying ahead of attackers requires more than just maintaining the status quo - it demands continuous improvement and proactive adjustments.
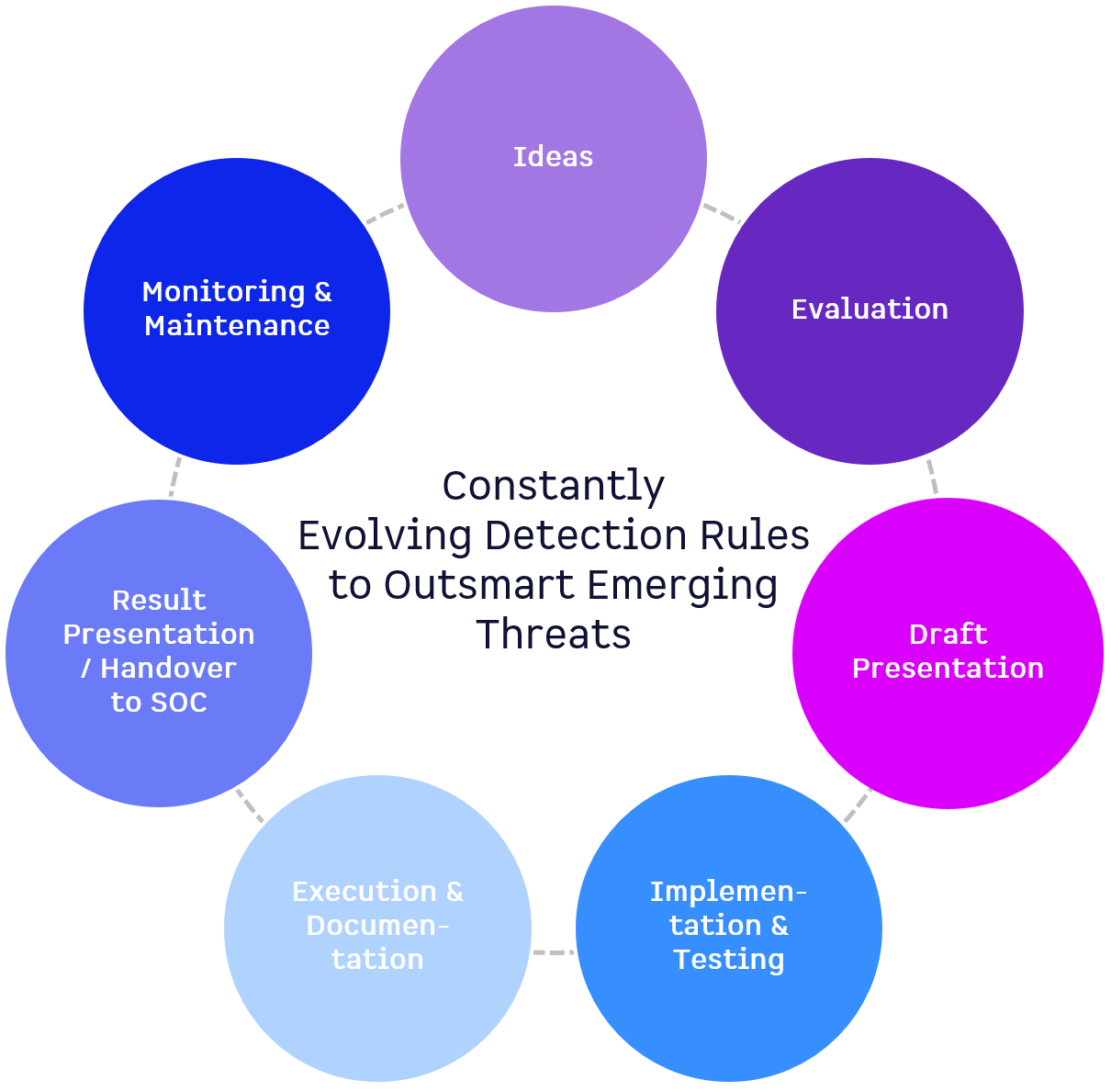
The process has the following phases:
- Ideas
- Evaluation
- Draft Presentation
- Implementation & Testing
- Execution & Documentation
- Result Presentation / Handover to SOC
- Monitoring & Main
Let’s break down each phase:
1. Ideas: Where It All Starts
This is the brainstorming phase where potential detection scenarios are identified. Ideas can stem from various sources, including:
- Threat Intelligence Reports: Insights from recent incidents or TI feeds.
- Red Team Exercises: Findings from simulated attacks.
- SOC Feedback: Input on gaps or recurring false negatives in existing detections.
- Emerging Organizational Needs: Changes in infrastructure, policies, or priorities.
- Ongoing Incidents: Reactive detections for current breaches.
- News/Blogs: Industry updates (a list of recommended sources will follow at the end).
The key here is fostering collaboration between SOC analysts, detection engineers and other stakeholders to create a pool of actionable ideas.
Real-Life Example:
Consider our ongoing incident where an employee unknowingly plugs a USB drive into a computer, leading to a breach (reactive approach). During this phase, documentation begins using a standardized template for consistency. Indicators of Compromise (IoCs) are essential for moving forward; if none exist, analyzing the attack path and its impact becomes critical.
IoCs from the XMRig Example:
- Frequent Usage of wscript.exe in Command-Line Calls:
- Description: wscript.exe is the Windows Script Host (WSH) executable for running VBScript (.vbs) or JScript (.js) files.
- Command Line String:
cmd.exe /c start wscript.exe //E:VBScript.Encode Logo.ico & start Assembly Planning.xlsx & exit - Processes:
- Creation of .lnk files flagged as malicious.
- Registry persistence via wscript.exe.
1. Evaluation: Is It Worth Pursuing?
In this phase, each idea undergoes a feasibility and impact assessment.
- Feasibility: Can the proposed detection logic be implemented with available tools and data sources?
- Impact: Will the rule reduce risk or address a significant gap?
A prioritization matrix can help determine which ideas to pursue first based on urgency and value. When dealing with ongoing incidents, reactive rules take top priority.
Detection Rules for the XMRig Example:
Encoded VBScript Executed:
Explanation: This KQL query retrieves and analyzes events where the process wscript.exe was executed, specifically focusing on cases where the command line includes the string "VBScript.Encode", which might indicate encoded VBScript execution (a common technique for obfuscation or malicious activity).
DeviceProcessEvents
| where InitiatingProcessFileName =~ "wscript.exe"
| where ProcessCommandLine contains "VBScript.Encode"
| order by Timestamp desc
| project Timestamp, DeviceName, AccountName, ProcessCommandLine, DeviceId, AccountUpn, ReportId
.lnk File Created by wscript.exe:
Explanation: This KQL query identifies events where wscript.exe was used to create .lnk (shortcut) files, a behavior often associated with phishing attacks, persistence mechanisms, or other malicious activities.
DeviceFileEvents
| where InitiatingProcessFileName =~ "wscript.exe"
| where FileName endswith ".lnk"
| where ActionType == "FileCreated"
| order by Timestamp desc
| project Timestamp, DeviceName, FileName, FolderPath, InitiatingProcessFileName, InitiatingProcessCommandLine, InitiatingProcessFolderPath, InitiatingProcessAccountName, DeviceId, InitiatingProcessAccountUpn, ReportId
Suspicious Autorun Entry Created:
Explanation: This KQL query is designed to detect suspicious modifications to registry keys, particularly those used for persistence mechanisms, by analyzing registry events involving the Run key in the Windows registry.
DeviceRegistryEvents
| where ActionType == "RegistryValueSet"
| where RegistryKey endswith @"\SOFTWARE\Microsoft\Windows\CurrentVersion\Run"
| where RegistryValueName == "AppSetup"
or InitiatingProcessFileName == "wscript.exe"
or RegistryValueData contains "wscript.exe"
or RegistryValueData endswith ".ico"
or RegistryValueData contains "VBScript.Encode"
| order by Timestamp desc
| project Timestamp, DeviceName, ActionType, InitiatingProcessFileName, RegistryValueName, RegistryValueData, InitiatingProcessAccountName, InitiatingProcessFolderPath, RegistryKey, DeviceId, InitiatingProcessAccountUpn, ReportId3. Draft Presentation: Share and Refine
Once an idea is approved, a draft rule or logic is created and presented to stakeholders for feedback. Stakeholders can be SOC analysts, TI team or the customer.
- What to Include:
- Preliminary detection logic (queries, conditions).
- Potential false positives and how they’ll be managed.
- Expected outcomes and use cases.
This ensures alignment and avoids duplicating efforts. With the feedback you can refine the detection rule.
4. Implementation & Testing: Make It Bulletproof
With stakeholder approval, the draft is implemented in a controlled environment.
- Testing Environment: Use a sandbox or non-production setup to simulate attacks and validate the rule. If you have no access to a test environment you can also check your detection rules with dry runs, but we recommend using a non-production setup.
- Key Checks:
- Does the rule trigger for legitimate threats?
- Are there unexpected false positives?
- Do we see any blind spots?
Iterative testing is crucial to fine-tune the detection logic before deployment.
5. Execution & Documentation: Make It Official
Once tested, the rule is deployed into production. Comprehensive documentation is critical at this stage:
- What to Document:
- Rule logic and conditions.
- Associated data sources.
- Expected alerts
- SOC playbooks
- Blind spots
- What can trigger a false positive
- How to respond to this incident
Proper documentation ensures that future updates or troubleshooting can be performed efficiently.
6. Result Presentation / Handover to SOC: Empower the Frontline
After deployment, the new detection rule is formally handed over to the SOC team.
- Presentation: Demonstrate how the rule works and what alerts to expect or give access to the documentation.
- Training: Provide training to ensure SOC analysts can interpret and act on alerts effectively.
- Feedback Loop: Create mechanisms for SOC teams to report issues or suggest improvements.
7. Monitoring & Maintenance: Stay Sharp
Deployment is not the end of the journey. Regular monitoring ensures the rule remains effective over time.
- What to Monitor:
- Changes in threat actor tactics.
- Shifts in organizational infrastructure.
- False positive or negative trends.
- Classification behavior.
- Continuous Improvement: Periodic reviews and updates to the rule keep it relevant in a dynamic threat landscape.
Periodic reviews and updates are essential for maintaining relevance and effectiveness. This phase focuses on refining detection logic to balance accuracy and efficiency, ensuring rules minimize noise while maximizing value to the SOC.
A key aspect of this phase is analyzing the performance of detection rules against classification metrics. Poorly performing rules can overwhelm the SOC with unnecessary alerts, defeating their purpose. The goal is to create and maintain rules that accurately detect threats while reducing operational burden.
By staying proactive in monitoring and maintaining detection rules, you can ensure your SOC remains agile and effective in responding to emerging threats.
Why a Defined Process Matters
A well-structured process like this ensures consistency, reduces blind spots, and minimizes reactive work. It empowers teams to address security challenges proactively while maintaining a clear focus on continuous improvement.
Lessons from the Field
- Invest in Proactive Measures: Leveraging threat intelligence can prevent known malware from slipping through.
- Educate Users: Teach employees to recognize suspicious files and devices.
- Streamline Detection Workflows: Build processes to reduce alert fatigue and ensure faster rule deployment.
Blogs to stay up-to-date
Conclusion: The Path to Smarter Security
Building effective custom detection rules isn’t just a technical task - it’s a critical investment in your organization’s resilience. By following a structured process, leveraging threat intelligence, and fostering collaboration, you can stay ahead of attackers and empower your SOC team to focus on what matters most: keeping your organization secure.
Custom detection rules are more than lines of code; they’re your first line of defense against evolving threats. Whether you’re crafting proactive measures to stop attacks before they happen or reactive rules to ensure incidents don’t repeat, the time and effort you invest today will pay dividends in safeguarding your environment.
Your Next Steps:
- Start reviewing your current detection processes - where can you improve?
- Engage your SOC team and stakeholders in brainstorming and refining detection ideas.
- Stay informed through trusted resources and continuously evolve your strategy.
Remember, security is a journey, not a destination. By adopting a proactive mindset and a clear process, you’re not just reacting to threats - you’re shaping the future of your organization’s defense.


